

Introduction
Retrieval Augmentation Generation (RAG) can enhance the capabilities of a Large Language Model (LLM) by incorporating a domain-specific informations that provides additional knowledge when the LLM generates a response. This integration can eliminates the need to retrain the model for specific knowledge.
In this article, we will explore the integration of RAG with a Llama 2 chatbot, deployed on Amazon SageMaker. We will leverage Amazon Bedrock to create embeddings, FAISS as vector store, and LangChain to establish the pipeline.
Use case
We will create a chatbot for HR recruiters that provides them with information about candidates by extracting the details from their resumes.
Text Extraction with Pdf Reader and LangChain
The first step in our journey is to extract text from PDF files, clean the extracted text, and split it into manageable chunks. This splitting is crucial due to the token limitations of embedding models. Finally, we save the results into a CSV file. Here's a Python script that accomplishes this task:
#!/usr/bin/env python3
from pypdf import PdfReader
import csv
import re
from langchain.text_splitter import RecursiveCharacterTextSplitter
MAX_TOKENS = 1000
CHUNK_OVERLAP = 0
PDF_FILE_PATH = "resume.pdf"
OUTPUT_CSV_PATH = "output.csv"
def clean_text(text):
# Define regular expression patterns for example: [xxxx]
refs_pattern = r"\[\s*\d+\s*(?:,\s*\d+\s*)*\]"
# Replace all patterns with empty strings
text = re.sub(refs_pattern, "", text)
# You can also remove newline characters
return text.replace("\n", " ")
# Extract the text from each page and add it to a list
def read_all_pages(reader):
texts = []
for page in reader.pages:
text = clean_text(page.extract_text())
splitted_text = RecursiveCharacterTextSplitter(
chunk_size=MAX_TOKENS, chunk_overlap=CHUNK_OVERLAP
).split_text(text)
texts.extend(splitted_text)
return texts
with open(PDF_FILE_PATH, "rb") as pdf_file:
# Extract text
reader = PdfReader(pdf_file)
texts = read_all_pages(reader)
# Write the text to a CSV file
with open(OUTPUT_CSV_PATH, "w", newline="") as csv_file:
writer = csv.writer(csv_file, delimiter="#")
writer.writerow(texts)Transforming Text Data into Embeddings
Once you have your text data extracted and cleaned, the next step is to convert it into embeddings.
Embeddings are numerical representations of text.
To achieve this, we'll use the model BAAI/bge-large-en.
This model can map any text into a low-dimensional dense vector, which can be utilized for retrieval, classification, clustering, or semantic search.
Additionally, we'll use the FAISS library to create a vector store of these embeddings and save it.
Below is the Python script to transform the text data into embeddings:
#!/usr/bin/env python3
from langchain.embeddings import HuggingFaceBgeEmbeddings
from langchain.vectorstores import FAISS
import csv
MODEL_NAME = "BAAI/bge-large-en"
MODEL_KWARGS = {"device": "cpu"}
ENCODE_KWARGS = {"normalize_embeddings": True}
CSV_FILE_PATH = "output.csv"
OUTPUT_INDEX_DIR_PATH = "output"
def load_text_from_csv(csv_file):
texts = []
with open(csv_file, "r") as f:
reader = csv.reader(f, delimiter="#")
for row in reader:
texts += row
return texts
embeddings = HuggingFaceBgeEmbeddings(
model_name=MODEL_NAME, model_kwargs=MODEL_KWARGS, encode_kwargs=ENCODE_KWARGS
)
texts = load_text_from_csv(CSV_FILE_PATH)
db = FAISS.from_texts(texts, embeddings)
db.save_local(OUTPUT_INDEX_DIR_PATH)When running the script for the first time it will download the model locally from Hugging Face.

After execution, you'll have a folder with two files: "index.faiss" and "index.pkl."
Testing the Embeddings Results
To ensure that the transformation of text data into embeddings is successful, we can perform a similarity search on a query. The following script demonstrates this process:
#!/usr/bin/env python3
from langchain.embeddings import HuggingFaceBgeEmbeddings
from langchain.vectorstores import FAISS
MODEL_NAME = "BAAI/bge-large-en"
MODEL_KWARGS = {"device": "cpu"}
ENCODE_KWARGS = {"normalize_embeddings": True}
OUTPUT_INDEX_DIR_PATH = "output"
embeddings = HuggingFaceBgeEmbeddings(
model_name=MODEL_NAME, model_kwargs=MODEL_KWARGS, encode_kwargs=ENCODE_KWARGS
)
db = FAISS.load_local(OUTPUT_INDEX_DIR_PATH, embeddings)
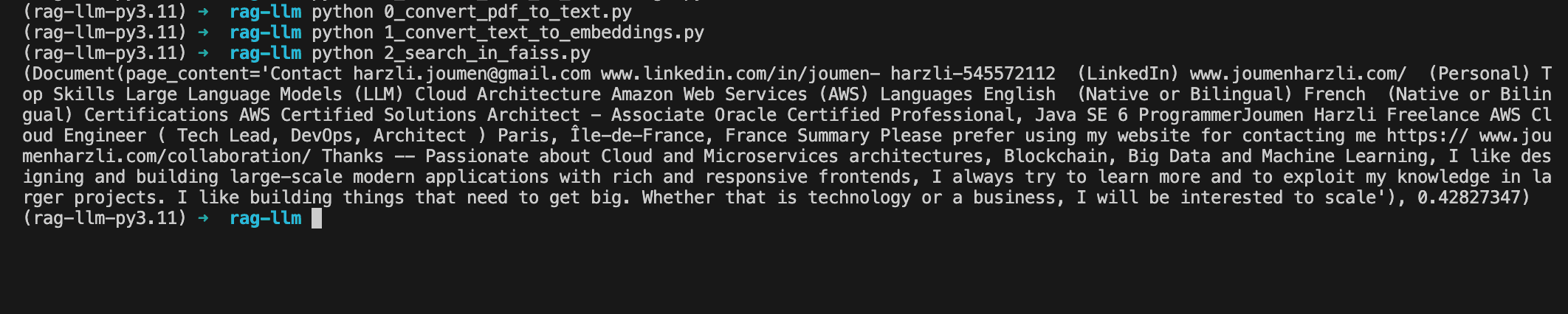
query = "What is the website of Joumen?"
results = db.similarity_search_with_score(query)
print(results[0])Here we can see results.
Using Amazon Bedrock for Text Embeddings
Now, if you're looking to industrialize this process, you can deploy the model on an AWS SageMaker endpoint. Fortunately, AWS recently introduced Amazon Bedrock, which offers others models for creating embeddings.
For our use case, we will use the model amazon.titan-embed-text-v1 which is a text embeddings model similar to BAAI/bge-large-en.
Requesting Access to Amazon Bedrock
Before you can use Amazon Bedrock, you need to request access from the Amazon Bedrock console.
Creating a vector store Using Amazon Bedrock
In this script, we'll use Bedrock to create a vector store by combining the scripts we've developed so far:
#!/usr/bin/env python3
import boto3
from langchain.embeddings import BedrockEmbeddings
from langchain.document_loaders import PyPDFLoader
from langchain.indexes import VectorstoreIndexCreator
from langchain.vectorstores import FAISS
PDF_FILE_PATH = "resume.pdf"
OUTPUT_INDEX_DIR_PATH = "output_bedrock"
BEDROCK_MODEL = "amazon.titan-embed-text-v1"
client = boto3.client(service_name="bedrock-runtime")
embeddings = BedrockEmbeddings(model_id=BEDROCK_MODEL, client=client)
loader = PyPDFLoader(PDF_FILE_PATH)
index_creator = VectorstoreIndexCreator(
vectorstore_cls=FAISS,
embedding=embeddings,
)
index_from_loader = index_creator.from_loaders([loader])
index_from_loader.vectorstore.save_local(OUTPUT_INDEX_DIR_PATH)Testing the Embeddings Results from Amazon Bedrock
We will update the search script to use Amazon Bedrock:
#!/usr/bin/env python3
import boto3
from langchain.embeddings import BedrockEmbeddings
from langchain.vectorstores import FAISS
BEDROCK_MODEL = "amazon.titan-embed-text-v1"
OUTPUT_INDEX_DIR_PATH = "output_bedrock"
client = boto3.client(service_name="bedrock-runtime")
embeddings = BedrockEmbeddings(model_id=BEDROCK_MODEL, client=client)
db = FAISS.load_local(OUTPUT_INDEX_DIR_PATH, embeddings)
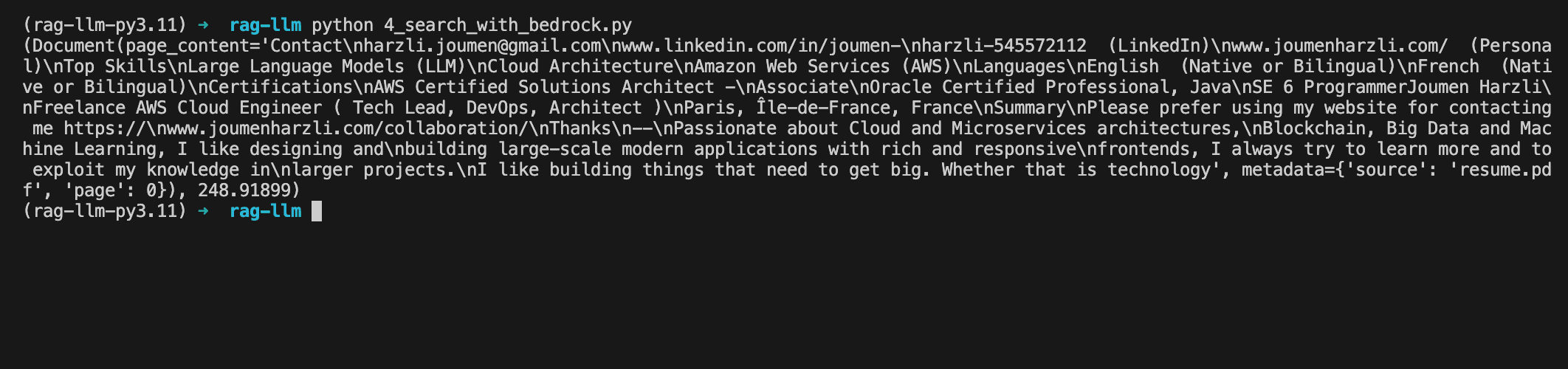
query = "What is the website of Joumen?"
results = db.similarity_search_with_score(query)
print(results[0])and here we have the results:
Using the vector store with the LLM Chatbot
If you've followed our previous article on Deploy Your Own Private LLM Chatbot, you'll have a SageMaker endpoint to interact with your chatbot. Now, it's time to integrate LangChain into your chatbot for Retrieval Augmented Generation (RAG).
Here, we'll create a Chat CLI using LangChain to provide context and manage chat history. LangChain enriches your prompts by incorporating context and chat history, ultimately improving the quality of responses from your LLM chatbot. The script creates a "ConversationalRetrievalChain" to interact with the LLM, the created FAISS vector store, and an ephemeral memory to store the chat history.
import boto3
import json
from typing import Dict
from langchain.embeddings import BedrockEmbeddings
from langchain.vectorstores import FAISS
from langchain.llms.sagemaker_endpoint import SagemakerEndpoint, LLMContentHandler
from langchain.chains import ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
# Constants for configuration
INDEX_DIR_PATH = "output_bedrock"
BEDROCK_MODEL = "amazon.titan-embed-text-v1"
SAGEMAKER_ENDPOINT_NAME = "my-huggingface-model-inference-endpoint"
MAX_TOKENS = 1024
MAX_CONTEXT_TOKENS = 500
TEMPERATURE = 0.6
TOP_P = 0.0
REPETITION_PENALTY = 1.2
class ContentHandler(LLMContentHandler):
content_type = "application/json"
accepts = "application/json"
def transform_input(self, prompt: str, model_kwargs: Dict) -> bytes:
print("-----------transform_input-----------------")
print(prompt.strip())
print("-----------/transform_input-----------------\n")
input_str = json.dumps({"inputs": prompt.strip(), "parameters": model_kwargs})
return input_str.encode("utf-8")
def transform_output(self, output: bytes) -> str:
response_json = json.loads(output.read().decode("utf-8"))
return response_json[0]["generated_text"].strip()
content_handler = ContentHandler()
bedrock_client = boto3.client(service_name="bedrock-runtime")
embeddings = BedrockEmbeddings(model_id=BEDROCK_MODEL, client=bedrock_client)
sagemaker_client = boto3.client("runtime.sagemaker")
llm = SagemakerEndpoint(
client=sagemaker_client,
endpoint_name=SAGEMAKER_ENDPOINT_NAME,
model_kwargs={
"max_new_tokens": MAX_TOKENS,
"temperature": TEMPERATURE,
"top_p": TOP_P,
"repetition_penalty": REPETITION_PENALTY,
"return_full_text": False,
},
content_handler=content_handler,
)
db = FAISS.load_local(INDEX_DIR_PATH, embeddings)
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
conversation_chain = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=db.as_retriever(),
memory=memory,
max_tokens_limit=MAX_CONTEXT_TOKENS,
)
while True:
user_input = input("Enter a message (or 'exit' to quit): ")
if user_input.lower() == "exit":
break
results = conversation_chain({"question": user_input})
print("-----------answer-----------------")
print(results["answer"])
print("-----------/answer-----------------")Here we can see the results, you can see how LangChain passed the context to your LLM.
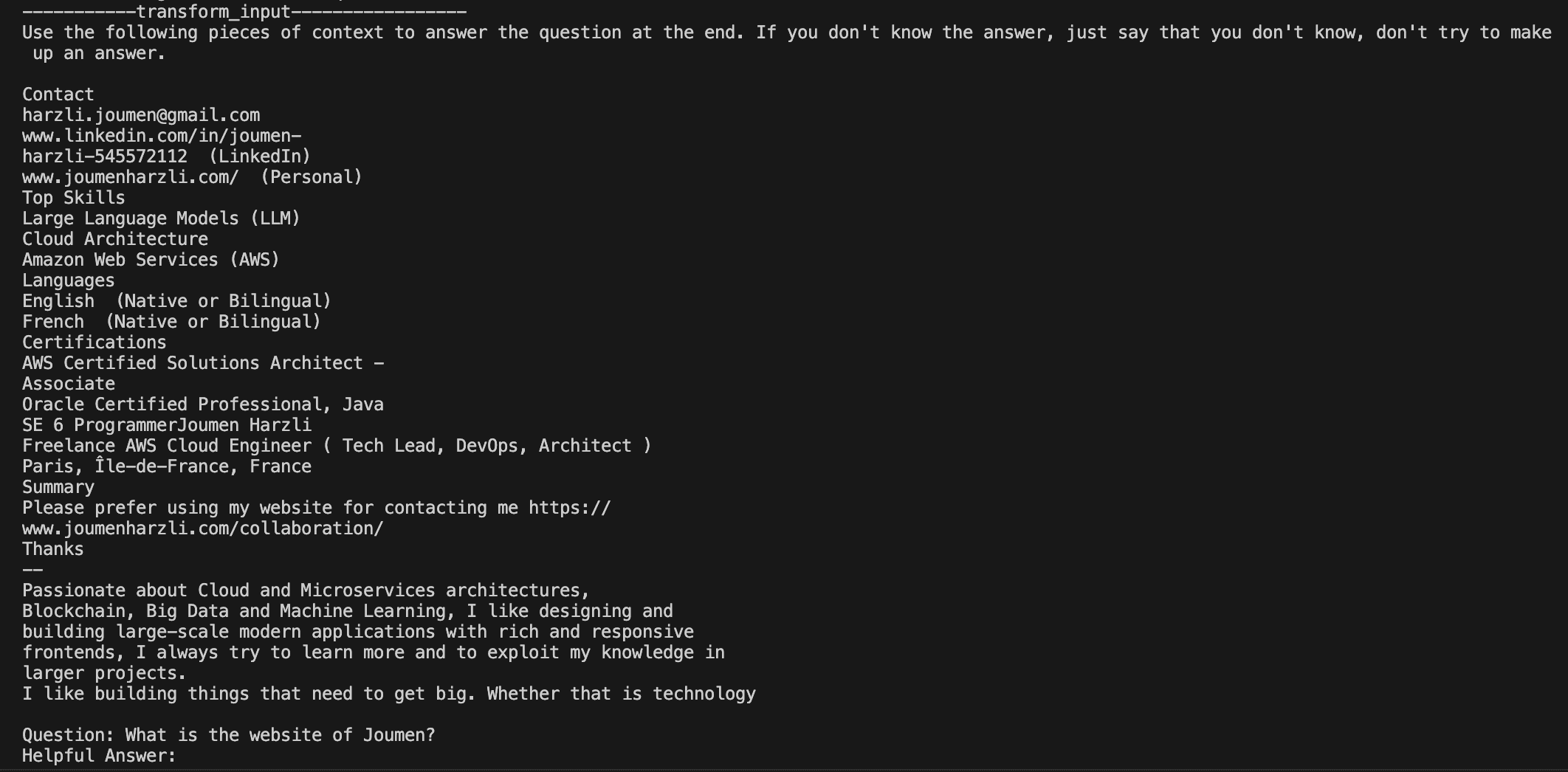
Creating a vector store Using an AWS Lambda
When dealing with multiple documents, it's convenient to automate the process of creating indexes upon document uploads to Amazon S3. You can achieve this using an AWS Lambda function. The current boto3 in the python lambda runtime dosen't recogine Amazon Bedrock, so i used a lambda container image to bypass the issue. Below is a sample Lambda script to create vector stores in an S3 bucket:
import boto3
import os
import logging
from langchain.embeddings import BedrockEmbeddings
from langchain.document_loaders import PyPDFLoader
from langchain.indexes import VectorstoreIndexCreator
from langchain.vectorstores import FAISS
logger = logging.getLogger()
BUCKET_NAME = os.environ["BUCKET_NAME"]
INDEXES_PREFIX = os.environ["INDEXES_PREFIX"]
BEDROCK_MODEL = "amazon.titan-embed-text-v1"
bedrock_client = boto3.client(service_name="bedrock-runtime")
s3_client = boto3.client("s3")
embeddings = BedrockEmbeddings(model_id=BEDROCK_MODEL, client=bedrock_client)
index_creator = VectorstoreIndexCreator(
vectorstore_cls=FAISS,
embedding=embeddings,
)
def lambda_handler(event, _):
try:
s3_event = event["Records"][0]["s3"]
object_key = s3_event["object"]["key"]
file_name = object_key.split("/")[-1]
file_path = f"/tmp/{file_name}"
index_dir_path = f"/tmp/index/{file_name}"
index_prefix = f"{INDEXES_PREFIX}/{file_name}"
logger.info(f"Downloading file {file_name}")
s3_client.download_file(BUCKET_NAME, object_key, file_path)
logger.info(f"Creating embeddings for file {file_name}")
loader = PyPDFLoader(file_path)
index_from_loader = index_creator.from_loaders([loader])
index_from_loader.vectorstore.save_local(index_dir_path)
logger.info(f"Uploading indexes for file {file_name}")
s3_client.upload_file(
f"{index_dir_path}/index.faiss",
BUCKET_NAME,
f"{index_prefix}/index.faiss",
)
s3_client.upload_file(
f"{index_dir_path}/index.pkl",
BUCKET_NAME,
f"{index_prefix}/index.pkl",
)
return {"status": "COMPLETE"}
except Exception as e:
logger.error(f"Error processing {file_name}: {str(e)}")
return {"status": "ERROR", "error_message": str(e)}Also, make sure to allow the lambda to invoke Amazon bedrock, read and write in your bucket.
data "aws_iam_policy_document" "lambda_role_policy" {
statement {
sid = "AllowInvokeBedrock"
effect = "Allow"
actions = ["bedrock:InvokeModel"]
resources = ["arn:aws:bedrock:*::foundation-model/amazon.titan-embed-text-v1"]
}
statement {
sid = "AllowReadObjects"
effect = "Allow"
actions = ["s3:GetObject*"]
resources = ["${aws_s3_bucket.bucket.arn}/files/*"]
}
statement {
sid = "AllowWriteIndexes"
effect = "Allow"
actions = ["s3:PutObject*"]
resources = ["${aws_s3_bucket.bucket.arn}/indexes/*"]
}
}By uploading a document under the "files" prefix, the Lambda function is triggered, and the vector store of the file is generated under "indexes/{file_name}."
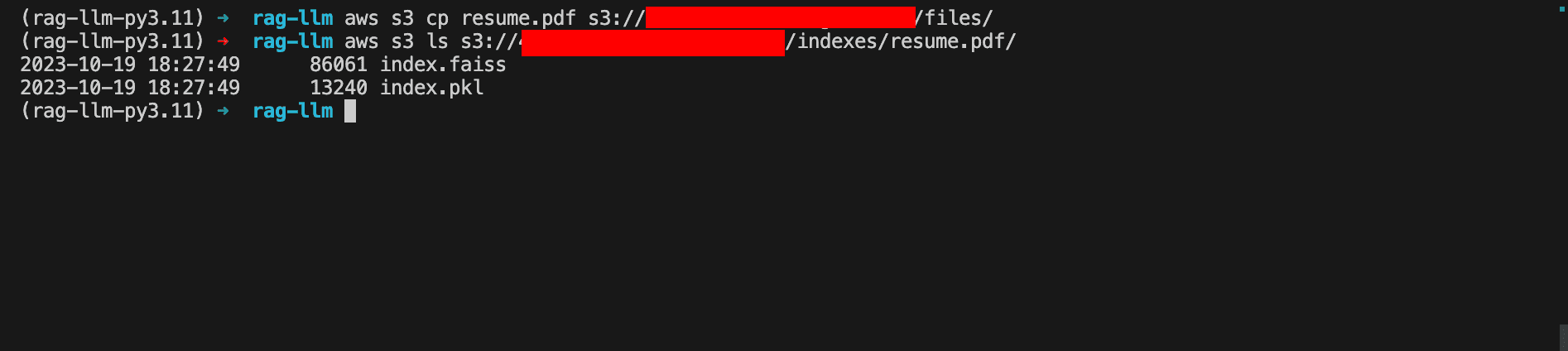
Integrating the Process into Streamlit
If you want to integrate this in Streamlit, you need to use the previous code in the chat cli to create the pipeline. You can use this code snippet to retrive the files from S3.
INDEX_DIR_PATH = "s3_outputs"
BUCKET_INDEXES_PREFIX = "indexes/"
def list_s3_files():
objects = s3.list_objects_v2(Bucket=BUCKET_NAME, Prefix=BUCKET_INDEXES_PREFIX)
files = [obj["Key"].split("/")[1] for obj in objects.get("Contents", [])]
return set(files)
s3_files = list_s3_files()
selected_file = st.sidebar.selectbox("Select a file", s3_files)
s3.download_file(
BUCKET_NAME,
BUCKET_INDEXES_PREFIX + selected_file + "/index.faiss",
f"{INDEX_DIR_PATH}/index.faiss",
)
s3.download_file(
BUCKET_NAME, BUCKET_INDEXES_PREFIX + selected_file + "/index.pkl", f"{INDEX_DIR_PATH}/index.pkl"
)
db = FAISS.load_local(INDEX_DIR_PATH, embeddings)Here we can see the results.
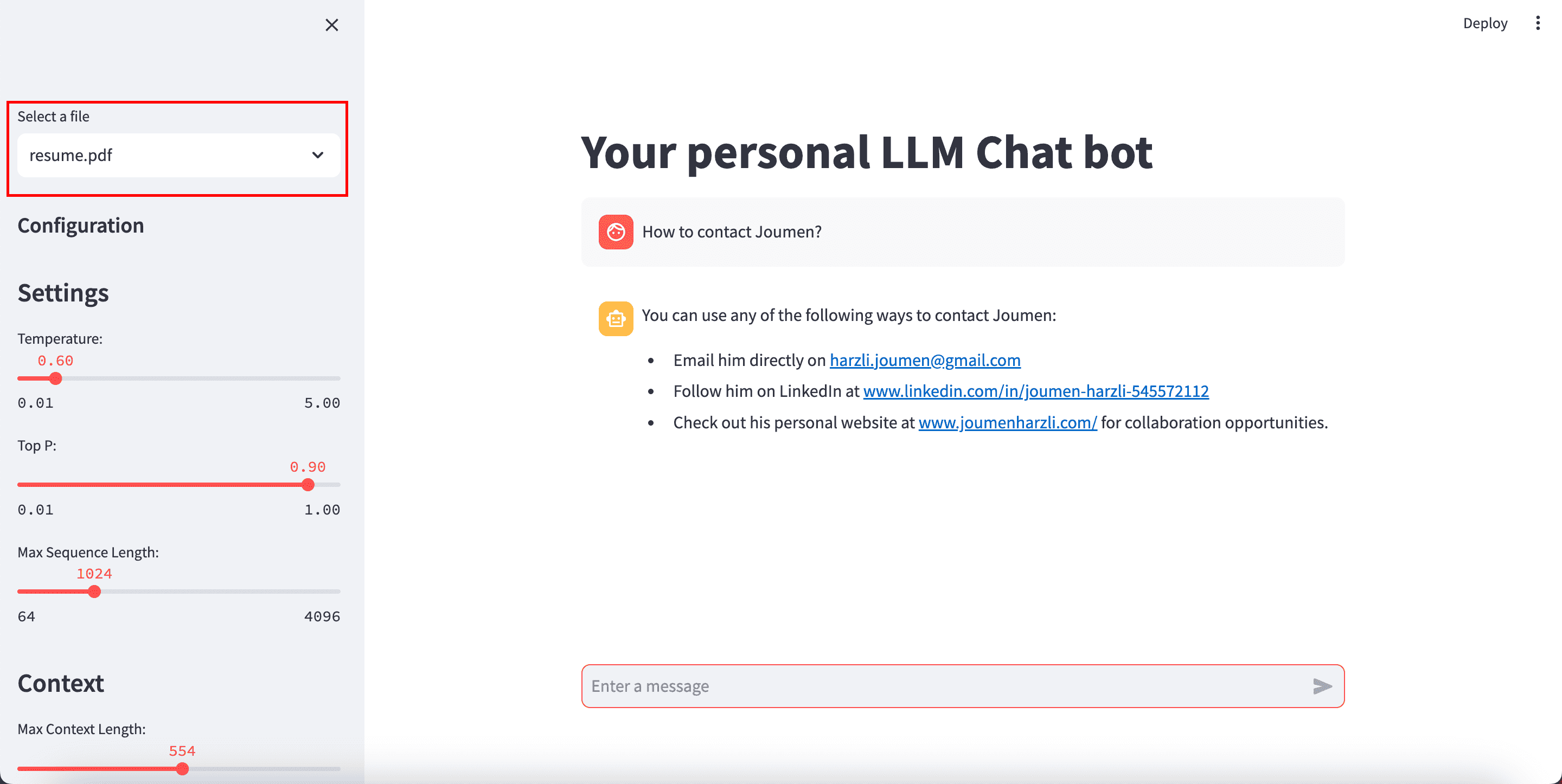
Conclusion
With these steps, you can unlock the power of Retrieval Augmentation Generation (RAG) in your Large Language Model (LLM) chatbot, making it more context-aware and responsive to user queries. By leveraging LangChain, Amazon Bedrock, AWS Lambda, and Streamlit, you can streamline the process and create a sophisticated chatbot that provides efficient responses. If you need assistance in integration RAG with private LLM chatbot, feel free to reach me out. I'm here to help!
Disclaimer
The information presented in this article is intended for informational purposes only. I assume no responsibility or liability for any use, misuse, or interpretation of the information contained herein.